K-means: Ejemplo de agrupación - Machine Learning con OpenCv y Python
Introducción:
Hello World!!! My name is Luis Salcedo. Bienvenidos a Mi Diario Python, el mejor blog para Aprender Python.
En el día de hoy haremos un articulo un poco... como decirlo... "Para amantes de los datos" . Veremos un ejemplo de agrupación de datos utilizando el método de agrupación "K-means", utilizado en el área del Aprendizaje Automático (Machine Learning).
Pero antes...
K-means... ¿Qué es eso?.
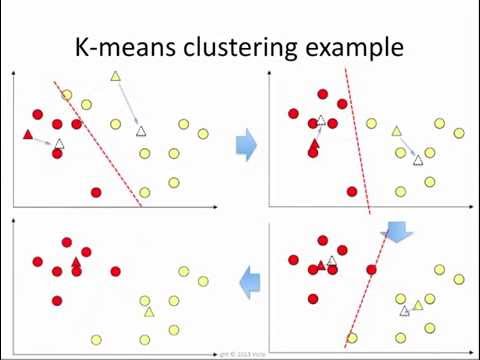
K-mans es un método de agrupación de datos, que tiene como objetivo la partición de un conjunto de n observaciones en k grupos en el que cada observación pertenece al grupo cuyo valor medio es más cercano. Este método es muy utilizado en la minería de datos.
Dado un conjunto de observaciones (x1, x2, …, xn), donde cada observación es un vector real de d dimensiones, k-means construye una partición de las observaciones en k conjuntos (k ≤ n) a fin de minimizar la suma de los cuadrados dentro de cada grupo (WCSS): S = {S1, S2, …, Sk}

donde µi es la media de puntos en Si.
Agrupamiento k-means cuando se usan heurísticas como el algoritmo de Lloyd es fácil de implementar incluso para grandes conjuntos de datos. Por lo que ha sido ampliamente usado en muchas áreas como segmentación de mercados, visión por computadoras, geoestadística, astronomía y minería de datos en agricultura. También se usa como preprocesamiento para otros algoritmos, por ejemplo para buscar una configuración inicial.
Implementación en Python con OpenCv:
Para la implementación del agrupamiento con K-menas, haremos uso de dos cosas:
- La librería opencv: la puedes descargar usando PyPi ingresando el siguiente comando en tu terminal: pip install opencv-python o puedes ingresar a: https://pypi.org/project/opencv-python/.
- El archivo gaussian_mix el cual puedes descargar ingresando aquí: https://github.com/LuisAlejandroSalcedo/k-means-opencv-python/.
Ahora podemos proseguir a escribir el código:
from __future__ import print_function import numpy as np import cv2 as cv from gaussian_mix import make_gaussians cluster_n = 5 # Numero de grupos img_size = 512 # Tamaño de la imagen # Generamos la paleta de colores colors = np.zeros((1, cluster_n, 3), np.uint8) colors[0,:] = 255 colors[0,:,0] = np.arange(0, 180, 180.0/cluster_n) colors = cv.cvtColor(colors, cv.COLOR_HSV2BGR)[0] while True: print("Ejemplo de distribución...") points, _ = make_gaussians(cluster_n, img_size) # Generamos los puntos term_crit = (cv.TERM_CRITERIA_EPS, 30, 0.1) ret, labels, centers = cv.kmeans(points, cluster_n, None, term_crit, 10, 0) img = np.zeros((img_size, img_size, 3), np.uint8) for (x, y), label in zip(np.int32(points), labels.ravel()): c = list(map(int, colors[label])) cv.circle(img, (x,y), 1, c, -1) cv.imshow('gaussian mixture', img) ch = cv.waitKey(0) if ch == 27: break cv.destroyAllWindows()
Al ejecutar el código, se creara una nueva ventana:

Cada vez que presiones "Espacio" se generaran nuevas agrupaciones:

Genial ¿No? Vemos que las agrupaciones que adaptan de manera muy precisa. Este tipo de métodos se utilizan para la clasificación.
Puedes descargar le código en formato ipynb ingresando aquí: https://github.com/LuisAlejandroSalcedo/k-means-opencv-python/.
¿Alguna duda? Entonces no dudes en dejar tu comentario.
Mi nombre es Luis, y fue un placer compartir mis conocimientos con todos ustedes :D.
Subir

Deja una respuesta