Introducción a las Redes Neuronales- Parte #1 - Tipos de Redes Neuronales
Tipos de Redes Neuronales
Perceptrón Simple:

Los pasos para que la red aprenda una lista de patrones son los siguientes
1 Tomar un patrón al azar de la lista.
2 Se establece el patrón de entrada en los sensores, la capa de entrada.
3 Se establecen los valores deseados en las neuronas de la capa de salida
4 Se actualizan las neuronas de la capa de Salida.
5 Solicitar que aprendan todas las sinapsis
6 Si las sinapsis han cambiado volver al paso 1
Si no han cambiado la red se ha estabilizado y paramos.
Las sinapsis que une las neuronas i, j aprenderá de la siguiente manera:
w = w + N * (d(k) - y) * x(k)
Donde:
W = El peso actual asociado a la sinapsis que une la neurona i de la capa de entrada y la neurona j de la capa de salida.
N = Es una constante entre 0 y 1 que indica cuanto aprende la red.
d(k) = El estado de la neurona de la capa de salida j.
y = El valor deseado para esa neurona.
x(k) = El estado de la neurona de la capa de entrada i.
El perceptrón simple tiene una serie de limitaciones, como lo es la incapazidad de clasificar conjuntos que no son linealmente independientes.
Por ello tenemos el Perceptrón Multicapa, y es aquí en donde nos topamos con otro tipo de red neuronal.
Perceptrón Multicapa
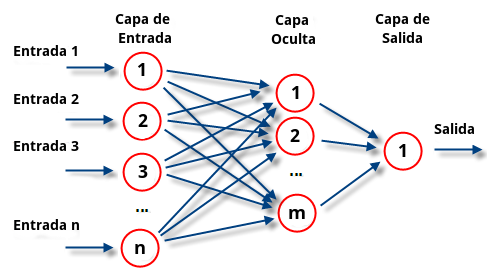
Este modelo es una ampliación del perceptrón a la cual añade una serie de capas que, básicamente, hacen una transformación sobre las variables de entrada, que permiten eludir el problema de no clasificar conjuntos que no son linealmente independientes.
La Red de Hopfield
La red de Hopfield es una de las redes unicapas más importantes y ha influido en el desarrollo de multitud de redes posteriores.
Es una red autoasociativa no lineal que fue desarrollada por Hopfield en 1982 basándose en los modelos de redes de McCulloch y Pitts y los símiles de los campos magnéticos con spin de Amit, Gutfreund, & Sompolinsky.
Arquitectura de la red de hopfield
La red de Hopfield es una red monocapa, esto es, de una sola capa. Aunque también se puede mostrar como una red bicapa de dos capas, la primera capa seria una capa de sensores y la segunda capa será la capa donde se realiza el procesamiento.
En la versión bicapa la manera de interconexionar ambas capas es unir la primera capa a la segunda linealmente, esto es cada neurona con su respectiva, y después unir todas las neuronas con todas en la misma capa.
La red de Hopfield toma valores bipolares esto es, {-1,1}, sin embargo se pueden usar también valores binarios {0,1}.
Ejecutar un patrón en la red de Hopfield consiste en enviar un patrón en la red y actualizar las neuronas repetidamente hasta que se estabilicen los estados de las neuronas a un patrón memorizado.
Con pasos sería así.
1 Se establece el patrón de entrada en la capa de entrada.
2. Se actualizan las neuronas de la capa de procesamiento.
3. Si han cambiado el estado de la red o hemos realizada ya el número máximo de iteraciones paramos.
4. Si no volvemos al pasos 2.
Redes Competitivas
Las redes de aprendizaje competitivo se diferencian de las otras redes neuronales en que en las anteriores redes las neuronas colaboran en la representación de los patrones, sin embargo, en este tipo de redes cada neurona compite con las otras neuronas para representar los patrones.
El aprendizaje de este tipo de redes es como su nombre indica, competitivo.
Las neuronas compiten en cual representa mejor al patrón y la ganadora se lleva todo el aprendizaje de ese patrón. El objetivo de este tipo de redes es que se formen grupos de patrones, categorías, que son representados por cada neurona.
Cuando ejecutamos un patrón en una red competitiva solamente se activa una neurona que es la que representa mejor el patrón.
Este tipo de redes fue desarrollado por Rumelhart y Zipser en 1985 aunque a partir de él se han diversificado sus aplicaciones y modificaciones dando lugar a redes tan interesantes como las redes de kohonen y otras.
Este es el ejemplo de red competitiva más simple que podemos encontrar ya que no introduce ninguna mejora.
Redes ART1
Las redes basadas en la teoría de resonancia adaptativa sirven para clasificar patrones de manera no supervisada, esto es, la red forma grupos y crea el número de categorías que crea conveniente en función de la configuración que le demos y las cualidades de los patrones.
Se considera que el aprendizaje no supervisado es el más posible desde un punto de vista psicológico, ya que los humanos aprendemos más sobre nuestra experiencia que escuchando a profesores. Un ejemplo de aprendizaje no supervisado es el siguiente: debemos clasificar una serie de objetos y no tenemos a nadie que nos diga a que categoría pertenece, así que tenemos que fijarnos en las características de los objetos y cuanto se parecen…
ART hace uso de dos términos usados en el estudio del comportamiento del celebro: Estabilidad y Plasticidad para llevar a cabo esta clasificación.
Estabilidad refleja la capacidad del sistema para recordar patrones previamente aprendidos. Plasticidad es la capacidad de aprender nuevos patrones
El equilibrio entre Estabilidad y Plasticidad es resuelto en las redes ART usando un parámetro llamado, granulidad , según algunos autores , otros lo llaman parámetro de vigilancia , yo he usado el anterior nombre por que expresa mejor la idea de una red con muchos categorías formando muchos y pequeños gránulos de patrones o formando pocos y grandes gránulos.
Este parámetro nos cuantifica cuanto debe diferenciarse un patrón al clasificar, del almacenado (estabilidad) en una categoría para que sea considerado una nueva categoría (plasticidad).
Redes ART2
La red ART2 es una ampliación de la red art1 que admite valores reales, como la anterior red, sirve para clasificar patrones de manera no supervisada
La arquitectura de la red ART2 es la misma que la de la art1. Consta de dos capas: la capa de entrada de sensores y la capa de salida, que en un principio no tiene ninguna neurona, pero que según vamos entrenando la red, esta va formando grupos de patrones que clasifica en una categoría cuyo patrón representativo son los pesos de entrada de la neurona de la capa de salida.
La manera de unirse ambas capas es total, cada neurona de la capa entrada esta unida con todas las neuronas de la capa de salida.
La diferencia principal entre la red art1 y la art2 es que esta última red admite valores reales.
Mapas de Kohonen. Redes Neuronales Autorganizativas.
La red de Kohonen pertenece a la categoría de redes no supervisadas, la diferencia con otras redes, es que las neuronas que representan patrones parecidos aparecen juntas en el espacio salida, este espacio puede ser unidimensional, una línea, bidimensional, un plano o N-dimensional. Es el propio diseñador de la red el que establece el espacio de salida que tendrá la red.
Las redes de kohonen son redes bicapas, esto es, de dos capas: la capa de entrada de sensores y la capa de salida que realiza el cálculo.
Cada neurona de la capa de salida debe reflejar las coordenadas que tiene en el espacio que el diseñador de la red decida. Para que las neuronas puedan ser comparadas con la posición de otras neuronas de la red, se le asocia una regla de vecindad.
El modo de unir las capas es todas con todas, total, cada neurona de la capa entrada esta unida con todas las neuronas de la capa de salida.
Referencias:
Deja una respuesta
Introducción a las Redes Neuronales - Parte #1: Topologia de la Redes Neuronales
1.4 Topología de las Redes Neuronales
1.4.1 Redes Monocapa
- la red de Hopfield
- la red de BRAIN-STATE-IN-A-BOX
- las maquinas estocasticas Botzmann y Cauchy.
- Entre otros

1.4.2 Redes Multicapa:
1.4.3 Conexiones entre neuronas
1.4.4 Redes de propagación hacia atras (backpropagation)
-
 Diego dice:
Diego dice: Me gustan mucho tus publicaciones sobre Redes Neuronales. Esperare la próxima entrada.
-
Unknown dice:
Agradecerte tu publicación por hacer más cercano ese mundo "nuevo" y extraño que son las Redes Neuronales.
-
Unknown dice:
HolA..!!! Como siempre...!!! muy bueno leer las publicaciones, aprender y sobretodo tambien difundir... En el Norte de Argentina tenemos un Grupo en Telegran @pythonnorte y alli posteo todas las publicaciones que generas...!! Gracias Luis...!! Te Seguimos..!!!
-
Alberto The Best dice:
Deseando que hagas la siguiente publicación!!!
Muchas gracias.
Deja una respuesta
Introducción a las Redes Neuronales: Parte #1 - Métodos de Aprendizaje
En este articulo nos centraremos en conocer los métodos de aprendizaje para el entrenamiento de las redes neuronales.
Como siempre, trata de explicarlo de manera clara sencilla, sin tantas expresiones matemáticas. Claro, es inevitable tener que colocar más de 3 formulas, ya que es muy importante conocer los procesos matemáticos de las redes neuronales. Sabes que si tienes alguna duda, puedes dejar un comentario, y con gusto responderé.
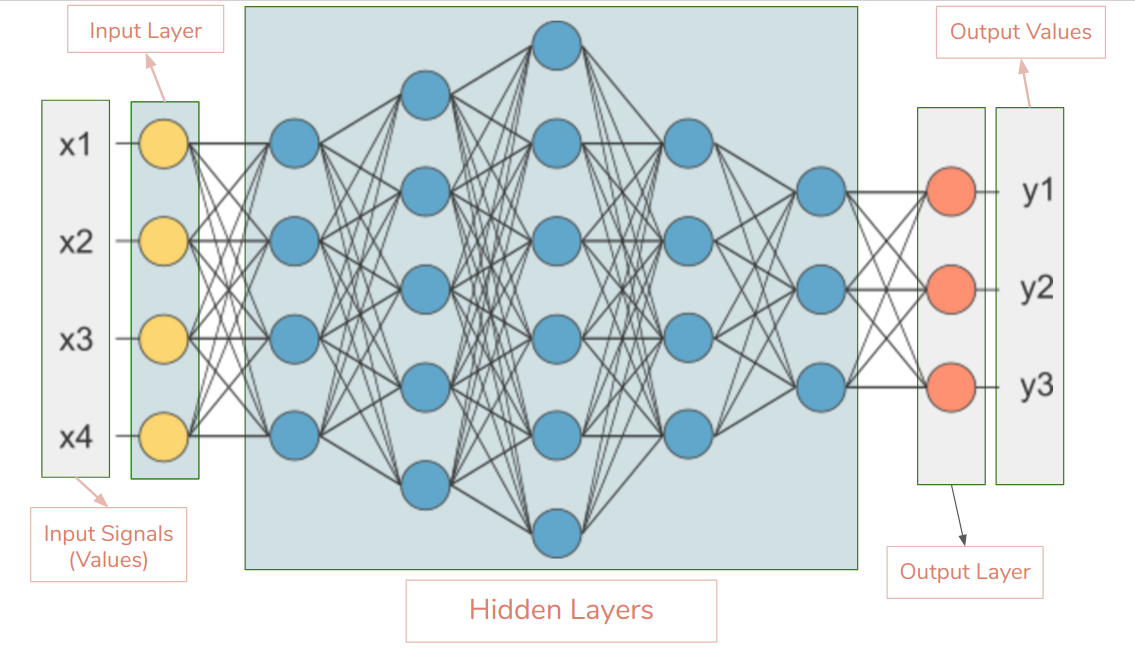
1.3 Métodos de Aprendizaje
- Aprendizaje Supervisado
- Aprendizaje no supervisado
1.3.1 Aprendizaje Supervisado
- Aprendizaje por corrección de error
- Aprendizaje por refuerzo
- Aprendizaje estocástico
1.3.1.1 Aprendizaje por corrección de error
1.3.1.2 Aprendizaje por refuerzo
1.3.1.3 Aprendizaje estocástico
1.3.2 Aprendizaje no supervisado
- Aprendizaje hebbiano.
- Aprendizaje competitivo y comparativo.
1.3.1.1 Aprendizaje hebbiano
1.3.1.2 Aprendizaje competitivo y comparativo
-
Unknown dice:
Umm. Lo leere mas tarde con calma. Podrías hacer según esto un mayordomo o algo así?. Ejemplo alguien virtual que responda cosas coherentes en una sala de chat?
Y que aprenda de las preguntas que se le hagan.? Umm eso es inteligencia Artificial. Plis muestrenme un pequeño código en python que haga algo parecido ...-
Luis Salcedo dice:
Hola. Por supuesto, nada es imposible. Claro, para crear un bot capaz de interpretar las preguntas y puede retornar respuestas coherentes, es un complicado ya implica muchos procesos incluyendo procesamiento del lenguaje natural que es otro tema amplio, en un futuro espero poder realizar un proyecto como ese y compartirlo. Pero si necesitas un bot como el que describes, te recomiendo https://dialogflow.com/ es una API mantenida por Google, es muy buena te la recomiendo, tienen implementaciones en diversos lenguajes (incluyendo python) también lo puedes integrar a Telegram, Facebook Messdenger, Google Assistant y mucho más.
-
-
Unknown dice:
Me encanta que alguien este investigando y realizar una red neural con python te doy mi apoyo esa idea de crear un cerebro virtual que pueda pensar estubo en mis ideas hace ya 2 años pero sigo estudiado un poco mas de lo que ya se.
Deja una respuesta
Introducción a las Redes Neuronales - Parte #1: Elementos básicos de una Red Neuronal
Segundo capitulo de la guía "introducción a las Redes Neuronales". En este capitulo 1.2 de la parte #1, veremos cuales son los elementos básicos que componen a una Red Neuronal.
1.2 Elementos básicos de una Red Neuronal

Las redes neuronales están interconectadas por 3 capas. La primera es la capa de entrada, la segunda son las capas ocultas, y por ultimo la capa de salida. Es importante saber, que las capas ocultas pueden estar constituidas por todas las capas que sean necesarias. Hay redes neuronales que utilizan cientos de capas ocultas. Claro, es un proceso más costoso, pero veremos cuales son los beneficios de esto más adelante.
Ahora les describiré las funciones que determinan una neurona y su proceso: función de entrada, función de activación y la función de salida.
Función de entrada:
recibe el nombre de entrada global. Esto nos genera un problema, como vamos a combinar todas estas simples entradas (ini1, ini2, ...) dentro de la entrada global (gin)?
productoria, etc.), n al número de entradas a la neurona Ni y wi al peso.
neurona. Por consiguiente, los pesos que generalmente no están restringidos cambian la
medida de influencia que tienen los valores de entrada. Es decir, que permiten que un
gran valor de entrada tenga solamente una pequeña influencia, si estos son lo
suficientemente pequeños.

1 a la neurona; w(1) = peso correspondiente a x1; x2 = entrada número 2 a la
neurona; w(2) = peso correspondiente a x2; y Y = salida de la neurona Ni. El
conjunto de todas las n entradas ini = (ini1, ini2, ..., inin) es comúnmente llamado “vector
entrada”.
son:
entrada a la neurona, multiplicados por sus correspondientes pesos.

entrada a la neurona, multiplicados por sus correspondientes pesos.

de entrada más fuerte, previamente multiplicado por su peso correspondiente.

Función de Activación
(Θi). A continuación describiré las 3 funciones de activación más comunes.

medio de esta función de activación serán:
a·(gini - Θi), cuando el argumento de (gini - Θi)
esté comprendido dentro del rango (-1/a, 1/a).
Por encima o por debajo de esta zona se fija la salida en 1 o –1, respectivamente.
t(x) = 1 si x≥ T
Donde T es el nivel de activación elegido.
proporciona esta función están comprendidos
dentro de un rango que va de 0 a 1. Al
modificar el valor de g se ve afectada la
pendiente de la función de activación.

tangente hiperbólica están comprendidos dentro de
un rango que va de -1 a 1. Al modificar el valor de g
se ve afectada la pendiente de la función de
activación.

activación está por debajo de un umbral determinado, ninguna salida se pasa a la
neurona subsiguiente. Normalmente, no cualquier valor es permitido como una entrada
para una neurona, por lo tanto, los valores de salida están comprendidos en el rango
[0, 1] o [-1, 1]. También pueden ser binarios {0, 1} o {-1, 1}.
- Ninguna: este es el tipo de función más sencillo, tal que la salida es la misma
que la entrada. Es también llamada función identidad. - Binaria: {0,1}
-
Anónimo dice:
que bien espero la próxima publicación
-
Anónimo dice:
A la espera del próximo artículo. Hace tiempo esperaba algo así. Estaba estudiando redes neuronales en un par de libros, aunque artículos así es lo mejor por su sencillez que, sin embargo, no dejan de lado conceptos importantes. Sigo el blog de hace unos 6 meses, y a verdad es que hacen un gran trabajo en cada artículo publicado. Sigan así. Muchas gracias!!
-
Unknown dice:
Sencillo, y muy provechoso el artículo
-
Diego dice:
Continuaré la lectura.
-
Unknown dice:
Gracias Luis, me pareció importante y pertinente para mi proyecto.
Deja una respuesta
Introducción a las Redes Neuronales - Parte #1: ¿Qué es una Red Neuronal?
Este articulo es la apertura a la guía de "Introducción a las redes neuronales", tema que eligieron nuestro usuarios en una encuesta realizada hace algunos días.
En este articulo les explicare como sera la estructura de la guía. Y veremos la primera parte de la guía "1.1 ¿Que es una Red Neuronal?".
Introducción:
- Parte #1 - No hay practica sin teoría: En toda esta parte, veremos toda la teoria y los conceptos necesarios para conocer el proceso de las redes neuronales, sus caracteristicas, sus tipos, y todo los lo que sea necesario conocer.
- Parte #2 - La practica hace al maestro: En esta parte, pondremos a prueba todos lo aprendido. Practicaremos los más que podamos. Construiremos nuestras propias redes y les daremos problemas del mundo real.
Parte #1 - No hay practica sin teoría
1.1 ¿Qué es una Red Neuronal?
- Visión Artificial
- Reconocimiento de voz
- Tablero de juegos y videojuegos
- Traducción automactica
- Diagnósticos médicos
- Procesamiento del lenguaje natural
- Clasificación de correo basura
- Clasificación de imágenes
- Creación de Chatbots
- Reconocimiento óptico de caracteres
- Y mucho más.
-
Unknown dice:
intersante, quiero mas...
-
Luis Salcedo dice:
Hola. Por supuesto, hay más de donde salio este. En el próximo veremos cual es el procedimiento utilizado para entrenar a una red neuronal.
Saludos.
-
Fernando Miño dice:
Bueno nos dejas con la expectativa y a la espera, gracias.
-
Diego dice:
Estoy siguiendo esta serie porque estoy leyendo sobre redes neuronales. Muy interesante. Gracias por tu trabajo.
-
Unknown dice:
Gracias siga así
-
Unknown dice:
Excelente aporte, esperamos mucho más sobre este tema, saludos cordiales.
Deja una respuesta
Estaría bien que incluyeseis un esquema de cada tipo de red, como para el perceptrón multicapa.