Introducción al Machine Learning #9 - K Vecinos más cercanos (Clasificación y Regresión)
Introducción:
Otra cosa que quisiera aclarar antes de comenzar, es que cuando me refiera a "K-NN", me estoy refiriendo a "K Vecinos más cercanos". K-NN es un abreviación de "K-Nearest Neighbors" ("Traducción de K Vecinos más cercanos").
Clasificación de vecinos más cercanos:
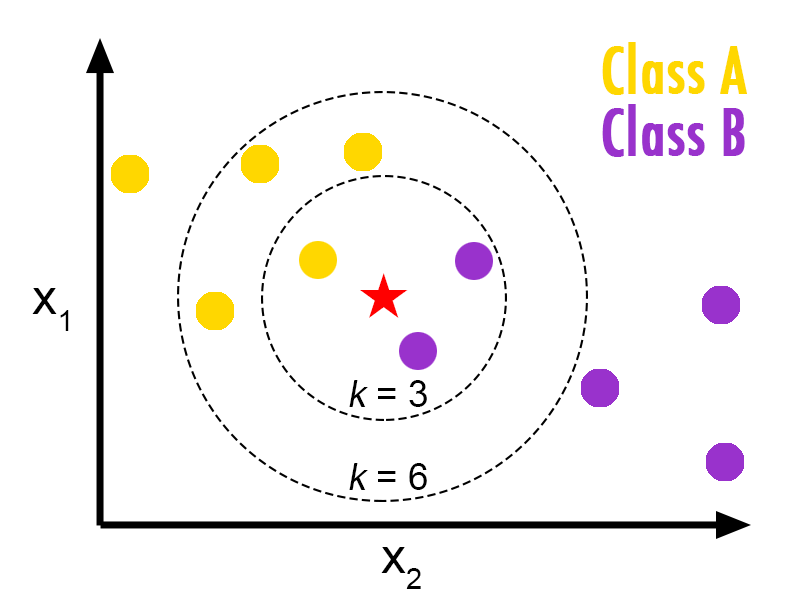
Figura 1.1
from sklearn.neighbors import KNeighborsClassifier #Importamos al método
from sklearn.datasets import load_iris #Importamos el conjunto de datos
from sklearn.model_selection import train_test_split
iris = load_iris() #Guardamos el conjunto de datos Iris en una variable
#Dividimos nuestros datos en "conjunto de entrenamiento y de prueba
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target)
knn = KNeighborsClassifier(n_neighbors=5) #Declaramos al método
knn.fit(x_train, y_train) #Ajustamos a al método
knn.score(x_test, y_test) # El porcentaje de acertamiento del método
Regresión de vecinos más cercanos:
Mientras que en la clasificación se trata de predecir valores discretos para Y (Ej: 1,2,3 y 4), en la regresión se predicen valores continuos (Ej: 222.6, 434.87, 300, 587 ...)
Ahora, realicemos un ejemplo con Python y Scikit-Learn.
import numpy as np
import matplotlib.pyplot as plt
from sklearn import neighbors
# Generamos los datos
np.random.seed(0)
X = np.sort(5 * np.random.rand(40, 1), axis=0)
T = np.linspace(0, 5, 500)[:, np.newaxis]
y = np.sin(X).ravel()
y[::5] += 1 * (0.5 - np.random.rand(8))
n_neighbors = 5 #Definimos el numero de vecinos que utilizaremos
for i, weights in enumerate(['uniform', 'distance']):
knn = neighbors.KNeighborsRegressor(n_neighbors, weights=weights) # Definimos al regresor
y_ = knn.fit(X, y).predict(T) # Lo entrenamos
# Graficamos los resultados
plt.subplot(2, 1, i + 1)
plt.scatter(X, y, c='k', label='data')
plt.plot(T, y_, c='g', label='prediction')
plt.axis('tight')
plt.legend()
plt.title("KNeighborsRegressor (k = %i, weights = '%s')" % (n_neighbors,
weights))
plt.show # Mostramos la grafica en pantalla

El ejemplo anterior, es una prueba de "KNeighborsRegressor". Como pueden observar, el resultado son 2 gráficas, esto por que en una al modelo se entrena con el atributo 'uniform' y al otros con el atributo 'distance'.
El método de KNN, es comúnmente usado para la clasificación, así que al momento de realizar regresión, KNN no sera tu primera opción.
Puedes leer más acerca de la clasificación y regresión viendo los siguientes artículos:
- https://www.pythondiario.com/2018/01/introduccion-al-machine-learning-7-los.html
- https://www.pythondiario.com/2018/01/introduccion-al-machine-learning-8.html
- http://scikit-learn.org/stable/modules/neighbors.html#classification
Dirígete a mi repositorio y ve todos los ejemplos presentados en este articulo: https://github.com/LuisAlejandroSalcedo/Pruebas_de_Machine_Learning_ScikitLearn.
Mi nombre es Luis, y fue un placer compartir mis conocimientos con todos ustedes :D.
Deja una respuesta
El método de clasificación de K-NN es realmente muy sencillo. Es usado para para problemas que nos requieran de muchos datos, ya que que K-NN tiene sus limitaciones. Que método hay para una mayor cantidad de datos más clasificaciones, algún sistema que conozcas ?