Introducción al Machine Learning #5 - Aprendizaje y Predicción
Índice
Introducción:
Muy bien, en artículos anteriores hemos visto los distintos algoritmos de aprendizaje, y la manera en la que debemos tener nuestros conjuntos de datos.
Llego la hora de el "Aprendizaje y Predicción", en el día de hoy entrenaremos a nuestro primer algoritmo, sera un ejemplo sencillo, pero nos ayudara a entender como funciona el problema de clasificación, y nos dará un poco de experiencia para los próximos artículos.
Para seguir leyendo este articulo, es necesario que leas el anterior en donde explico de que manera manipular los conjuntos de datos, y la importancia que tienen en el rendimiento de nuestro algoritmo. Conjuntos de Datos.
El algoritmo que quería aprender:
Perfecto, ya tenemos los conocimientos suficientes para entrar al mundo del "Aprendizaje y Predicción".
En el día de hoy, realizaremos un pequeño ejemplo. Entrenaremos a un clasificador con el conjunto de datos Iris, para que al ingresar nuevos datos sin etiquetar (Las medidas da la flor), el clasificador pueda predecir a que tipo de Iris podría pertenecer los datos de la flor ingresada. Por ello "Aprendizaje y Predicción", el algoritmo aprenderá, para luego poder "predecir".
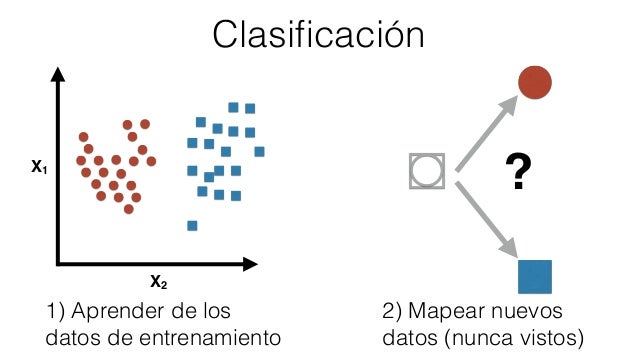
Muy bien, leyendo el párrafo de arriba, nos damos cuenta de que estamos tratando con un problema de clasificación, que se encuentra dentro del "Aprendizaje Supervisado". Existen muchos algoritmos que pueden resolver este sencillo problema de clasificación, pero esto no significa que usaremos uno solo algoritmo para resolver todo tipo de problema, siempre debemos escoger el algoritmo que tenga más rendimiento al momento de resolver nuestro problema.
Como lo que haremos hoy sera un ejemplo, solo nos preocuparemos de que el algoritmo aprenda de una forma adecuada.
Para el ejemplo de hoy utilizaremos las Maquinas de Vectores de Soporte, de esta manero, aprovecho de explicar este conjunto de algoritmos.
Maquinas de Vectores de Soporte (SVM):
Antes de realizar el ejemplo, es esencial saber como funciona lo que haremos.
Las maquinas de vectores de soporte, son un conjunto de algoritmos de aprendizaje supervisado. Aunque principalmente fueron pensados para resolver problemas de clasificación, actualmente se utilizan para resolver otros tipos de problemas como: Regresión, agrupación y multiclasificación. También son diversos los campos en donde son aplicadas con éxito como: Visión artificial, reconocimiento de caracteres, procesamiento del lenguaje natural, clasificación de proteínas, entre otros.
La maquinas de vectores de soporte, son muy eficientes, pero siempre se deberán considerar otras opciones, y escoger la que mejor se adapte a tus necesidades.
Las SVMs, tienen sus ventajas y desventajas, a continuación te nombro algunas:
Las ventajas de las máquinas de vectores de soporte son:
- Efectivo en espacios de alta dimensión.
- Sigue siendo efectivo en casos donde el número de dimensiones es mayor que el número de muestras.
- Utiliza un subconjunto de puntos de entrenamiento en la función de decisión (llamados vectores de soporte), por lo que también es eficiente desde el punto de vista de la memoria.
- Versátil: se pueden especificar diferentes funciones del Kernel para la función de decisión. Se proporcionan núcleos comunes, pero también es posible especificar kernels personalizados.
Las desventajas de las máquinas de vectores de soporte incluyen:
- Si la cantidad de funciones es mucho mayor que la cantidad de muestras, evite el ajuste excesivo al elegir las funciones Kernel y el término de regularización es crucial.
- Las SVM no proporcionan estimaciones de probabilidad directamente, estas se calculan utilizando una costosa validación cruzada de cinco veces
Bien, eso es información suficiente, por ahora.
Mi Primer Clasificador:
Bien, como mencione anterior los SVMs, son usados en muchas áreas. Pero nosotros nos limitaremos a clasificar datos.
Para el ejemplo de hoy, utilizaremos el lenguaje de programación Python junto al modulo skelarn.
Perfecto, como siempre, empezamos importando los módulos que utilizaremos:
from sklearn import svm from sklearn.model_selection import train_test_split from sklearn.datasets import load_iris
Lo primero que importamos es el conjunto de algoritmos SVM. Luego importamos el método "train_test_split()", el cual nos permite separa nuestro conjuntos de datos en, conjunto de entrenamiento y conjunto de prueba, este tema fue discutido en el articulo anterior (Introducción al Machine Learning #4 - Conjuntos de Datos), por ello, no entrare en muchos detalles. por ultimo importamos el conjunto de datos Iris, con el cual alimentaremos a nuestro algoritmo.
Lo siguiente que hacemos es ordenar nuestros datos, guardamos los datos en una variable llamada "iris", seguidamente dividimos este conjunto de datos con ayuda del metodo "train_test_split()".
iris = load_iris() x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target)
Recordemos que en las variable "x_train" y "x_test" se encuentran las medidas de las plantas, mientras que en "y_train" y "y_test" se encuentran las etiquetas con las cuales etiquetaremos esos datos.
Luego de tener los datos, ya podríamos entrenar a nuestro algoritmo, pero antes de eso debemos definir que algoritmo utilizaremos.
clf = svm.SVC()
En esta parte, definimos una variable llamada "clf" (abreviación de clasificador), esta variable representara a nuestro algoritmo. Como menciona anteriormente, las SVMs son utilizadas para la resolución de diversos problemas, y se debe especificar cual es cual, en este caso utilizamos SVM (Clasificación de Vectores de Soporte), ideal para nuestro problema de hoy.
Perfecto, tenemos los datos, el algoritmo, ahora ¿Que falta?. Sí, entrenarlo, para entrenar nuestro algoritmo, simplemente utilizamos el metodo "fit", al cual le pasamos como argumento, los datos (x), y las etiquetas (y).
clf.fit(x_train, y_train)
Out[4]:
Excelente, como pueden observar, se nos muestra una salida, la cuales son los atributos del algoritmo, en un futuro, veremos cual es la importancia y como influyen los valores de estos atributos, en el entrenamiento de nuestro algoritmo.
Muy bien, ya hemos entrenado a nuestro algoritmo. Antes de hacer predicciones, veamos que tan bien aprendió el algoritmo.
clf.score(x_test, y_test)
Out[5]:
Con el método "score", podemos ver que tan bien aprendió el algoritmo, el método recibe 2 argumentos, los datos (x) y las etiquetas (y). Por esa razón separamos nuestro conjunto de datos. Recordemos que los datos "x_test" y "y_test" son desconocidos por el algoritmo, por ello se utilizan para ver la capacidad que tiene el algoritmo al momento de predecir datos nuevos.
El resultado es de un 97 por ciento, ese es el porcentaje de la precisión de nuestro algoritmo. Así que vemos que el algoritmo aprendió bien.
Por ultimo, pidamos al algoritmo que clasifique una entrada nueva introducida por nosotros:
clf.predict([[6.8, 3.2, 5.9, 2.3]])
Out[9]:
Con el método "predict", el algoritmo etiquetara a grupo de Iris pertenecen esos datos. Los datos que e ingresado no los conoce el algoritmo, ya que los obtuvo desde el conjunto de prueba. El resultado es 2, lo cual significa que el algoritmo clasifica estos datos en el grupo de iris Virginica. Lo cual es correcto.
Utilizando:
iris.target_names
Out[10]:
Podremos saber cuales son los tipo de Iris, si el algoritmo nos muestra la salida 1 sabremos que se refiere al tipo "setosa", 1 es "versicolor" y 2 es "virginica". Este tema fue explicado con más precisión en el articulo anterior.
Bueno, creo que eso esta bien por hoy. Los SVMs son muy importantes en el Aprendizaje Automático, tienen una gran variedad de aplicaciones, y téngalo por seguro, que lo veremos más a fondo en artículos posteriores.
En este blog, hace un tiempo, escribí un articulo sobre el reconocimiento de dígitos escritos a mano, en el cual se hace uso de SVM, te recomiendo que lo leas, es una buena practica:
Bueno, con esto no podemos crear a nuestro primer "terminator", pero es un comienzo.
Mi nombre es Luis, es fue un placer compartir mis conocimientos con todos ustedes :D.
Subir

Deja una respuesta